适用于版本2.3.0
1 概览
(1) SQL
查询结果以Dataset/DataFrame形式返回。
可以通过命令行command-line或JDBC/ODBC连接
(2) Dataset和DataFrame
1) Dataset
DataSet是分布式数据集合。
可从JVM对象生成。
Python和R暂时只能间接实现类似功能。
2) DataFrame
是使用命名的列组织的Dataset.
等同于关系型数据库中的表和Pathon/R中的data frame.
Scala中表示为Dataset[Row]的别名DataFrame,Java中表示为Dataset\
2 入门
(1) Spark Session
SparkSession是Spark SQL的入口。
在版本2.0中提供了Hive支持。如使用HiveQL查询、访问Hive UDF和从Hive表中读取数据。
1 | import org.apache.spark.sql.SparkSession |
(2) 创建DataFrame
从JSON数据中创建
1 | val df = spark.read.json("examples/src/main/resources/people.json") |
(3) DataFrame操作
即无类型数据集操作
示例如下
1 | // This import is needed to use the $-notation |
(4) 编码SQL查询
sql语句作为参数传递。示例如下
1 | // Register the DataFrame as a SQL temporary view |
(5) 全局临时视图
通常,临时视图的生命周期仅限于当前会话。
全局临时视图将视图绑定到系统保存的数据库global_temp。使用时必须使用限定的名称引用。
全局临时视图可以在会话间共享。
1 | // Register the DataFrame as a global temporary view |
(6) 创建Dataset
Dataset适用于RDD不同的序列化方式Encoder,能够直接过滤、排序或哈希,而不需要反序列化。
1 | case class Person(name: String, age: Long) |
(7) RDD间操作
RDD转换为DataFrame
反射推断
适用于运行前已知模式
使用样例类
编程指定
适用于运行前未知模式
使用StructureType
1) 使用反射推断模式
1 | // For implicit conversions from RDDs to DataFrames |
2) 指定模式
构建模式。
- 创建模式
- 将记录转换为行RDD
- 应用模式到行RDD
1 | import org.apache.spark.sql.types._ |
(8) 聚合
1) 无类型用户自定义聚合函数
通过实现抽象类UserDefinedAggregateFunction
1 | import org.apache.spark.sql.{Row, SparkSession} |
2) 类型安全用户自定义聚合函数
用于与强类型数据集交互
通过实现 Aggregator
1 | import org.apache.spark.sql.expressions.Aggregator |
3 数据源
将DataFrame注册为临时视图,可以在其上进行SQL查询。
(1) 通用加载/保存函数
默认使用parquet作为数据源,可通过spark.sql.sources.default修改。
1 | val usersDF = spark.read.load("examples/src/main/resources/users.parquet") |
1) 人工指定选项
数据源通过全限定名指定(如org.apache.spark.sql.parquet),内建的数据源可以使用短名称(如json, parquet, jdbc, orc, libsvm, csv, text)
1 | // JSON |
2) 直接在文件上执行SQL
不用加载到DataFrame,就可以执行SQL查询
1 | val sqlDF = spark.sql("SELECT * FROM parquet.`examples/src/main/resources/users.parquet`") |
3) 保存模式
指定数据存在时的行为。
以下行为不是原子的,也没有使用锁。
覆盖时,先删除再写入。

4) 保存到持久化表中
持久化表在Spark程序重启后依旧可用,不同于临时视图。
DataFrame可以使用saveAsTable方法持久化到Hive Metastore中。
通过SparkSession的table方法按名称调用持久化表。
不需要单独部署Hive。Spark将创建使用Derby创建本地Hive Metastore。
基于文件的数据源,可以指定路径。如df.write.option(“path”, “/some/path”).saveAsTable(“t”)。删除表后,路径和文件依旧存在。
没有指定路径时,Spark将数据写入到仓库目录的默认表路径。删除表后,默认表路径也删除。
版本>=2.1,持久化表具有存储在Hive Metastore中的分区元数据。可以:
- 不需要在首次查询时扫描所有分区,因为Metastore可以只返回需要的分区。
- 可以使用Hive DDL
注意:创建外部数据源表(使用path选项)时,默认不聚集分区信息。可以使用MSCK REPAIR TABLE同步。
5) 分组(Bucket)、排序和分区
分组和排序只能用于持久化表。
分组将数据分布在固定数量的桶中。
分区对唯一值数量敏感,即对具有高基数的列的适用性有限。
可以同时使用分组和分区。
Spark 3.0
partittionBy创建了分区发现一节中描述的目录结构,因此限制了高基数的列的可用性。
bucketBy在固定数量桶中分散数据,可以用于唯一值数量没有边界的的场景
注意:bucketBy使用了列的哈希值分桶,保证具有相同哈希值的记录在同一个桶中,可以避免shuffle。
1 | peopleDF.write.bucketBy(42, "name").sortBy("age").saveAsTable("people_bucketed") |
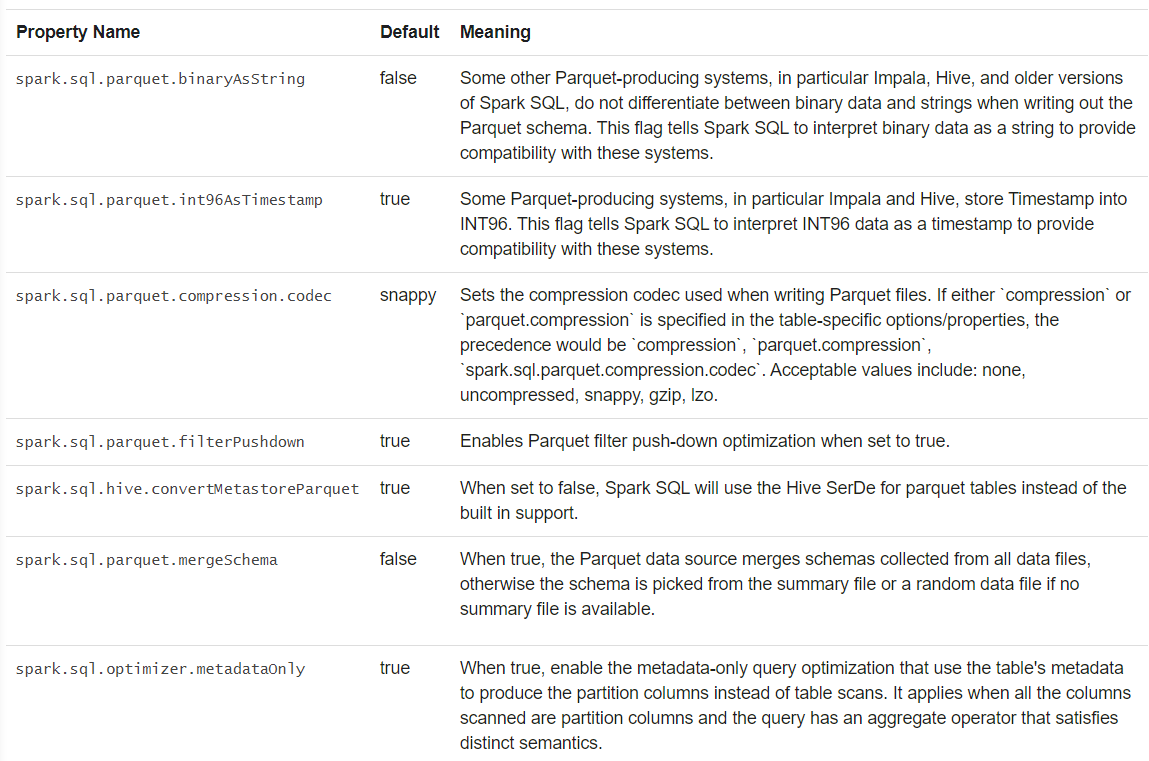
(2) Parquet文件
Parquet是列格式的数据。自描述格式,保存有模式信息。
当写入Parquet文件文件时,为了适配,将列自动转换为可为空。
1) 数据加载
1 | // Encoders for most common types are automatically provided by importing spark.implicits._ |
2)分区发现
Hive之类的系统使用表分区作为一种通用优化手段。
分区表使用分区列将数据分散到不同的目录中。
内建文件数据源(Text/CSV/JSON/ORC/Parquet)支持自动发现和推断分区信息。
如使用gender和county作为分区列,分区表目录如下:
1 | path |
传递参数path/to/table到SparkSession.read.parquet或SparkSession.read.load,可以自动从路径中提取分区和模式信息。提取的模式信息如下:
1 | root |
分区列数据类型当前支持数值、日期、时间戳和字符串类型。
通过spark.sql.sources.partitionColumnTypeInference.enabled关闭自动推断。关闭后,将使用字符串作为分区列类型。
版本>=1.6,默认只发现传递的目录参数中的分区。子目录也不能发现。可以通过数据源的basePath选项更改。
3) 模式合并
自动检测并合并兼容的Parquet数据源。
版本>=1.5,默认关闭。
开启方法:
1 读取时,设置数据源选项mergeSchema为true
2 设置全局SQL选项spark.sql.parquet.mergeSchema为true
1 | // This is used to implicitly convert an RDD to a DataFrame. |
4) Hive元数据存储Parquet表转换
为了性能,Spark使用自身的Parquet支持替代Hive的SerDe。通过spark.sql.hive.convertMetastoreParquet开关。
1’ Hive/Parquet模式调和(reconciliation)
Hive与Parquet模式区别:
- Hive大小写敏感,而Parquet不是。
- Hive所有列是可为空的,而Parquet不是。
调和规则:
- 同名列必须数据类型相同,并且是否为空和Parquet相同。
- 字段与Hive Metastore保持一致
- 仅在Parquet中出现的字段被删除
- 仅在Hive中出现的字段被添加
2’ 元数据刷新
为了性能,Spark SQL缓存元数据。需要人工刷新:
1 | // spark is an existing SparkSession |
5) 配置
- 使用SparkSession的setConf
- 在SQL脚本中,使用SET key=value
(3) ORC文件
版本>=2.3,支持一种矢量化的ORC读取器,用于读取ORC文件。
本地ORC表(如使用USING ORC创建的)
spark.sql.orc.impl->native
spark.sql.orc.enableVectorizedReader->true
Hive(如使用USING HIVE OPTIONS创建的)
spark.sql.hive.convertMetastoreOrc->true

(4) JSON数据集
Spark使用的JSON格式与典型格式有所区别,详见JSON Lines text format, also called newline-delimited JSON.
其采用UTF-8编码,要求每一行采用\n分隔,并且每一行都是合法的JSON值。
使用多行JSON,需要设置multiLine为true.
1 | // Primitive types (Int, String, etc) and Product types (case classes) encoders are supported by importing this when creating a Dataset. |
(5) Hive表
Hive依赖库需要在所有节点可用,如使用序列化与反序列化库
Hive配置:将hive-site.xml(用于连接外部Hive)、core-site.xml(用于安全配置)和hdfs-site.xml(用于HDFS访问)放置到conf目录中。
初始化SparkSession时需要开启Hive支持。其中包括连接到持久化Hive Metastore、Hive Serdes和用户自定义函数。
没有hive-site.xml配置时,Spark在spark.sql.warehouse.dir(默认是程序运行目录下的spark-warehouse文件夹)创建metastore_db。
版本>=2.0, Spark使用spark.sql.warehouse.dir替换Hive配置中的hive.metastore.warehouse.dir。
启动程序的用户需要授予写权限。
1 | import java.io.File |
注意:
- Hive版本>=0.9默认开启自动分区。严格模式需要指定静态分区列,而非严格模式不需要。默认有相应的分区数量限制。
- Hive 3.0不需要指定动态分区列,因为会自动创建。
1) 指定存储格式
创建Hive表时,需要指定存储格式和序列化方式,如 CREATE TABLE src(id int) USING hive OPTIONS(fileFormat 'parquet')
读取默认按照文本格式。
当前不直接支持Hive storage handler。可以先在Hive端创建表,Spark SQL再读取

2) 与不同版本Hive Metastore交互
Spark可以通过配置与不同的Hive Metastore交互。
在内部,Spark基于Hive1.2.1编译,使用其内部执行,如serdes、UDF和UDAF
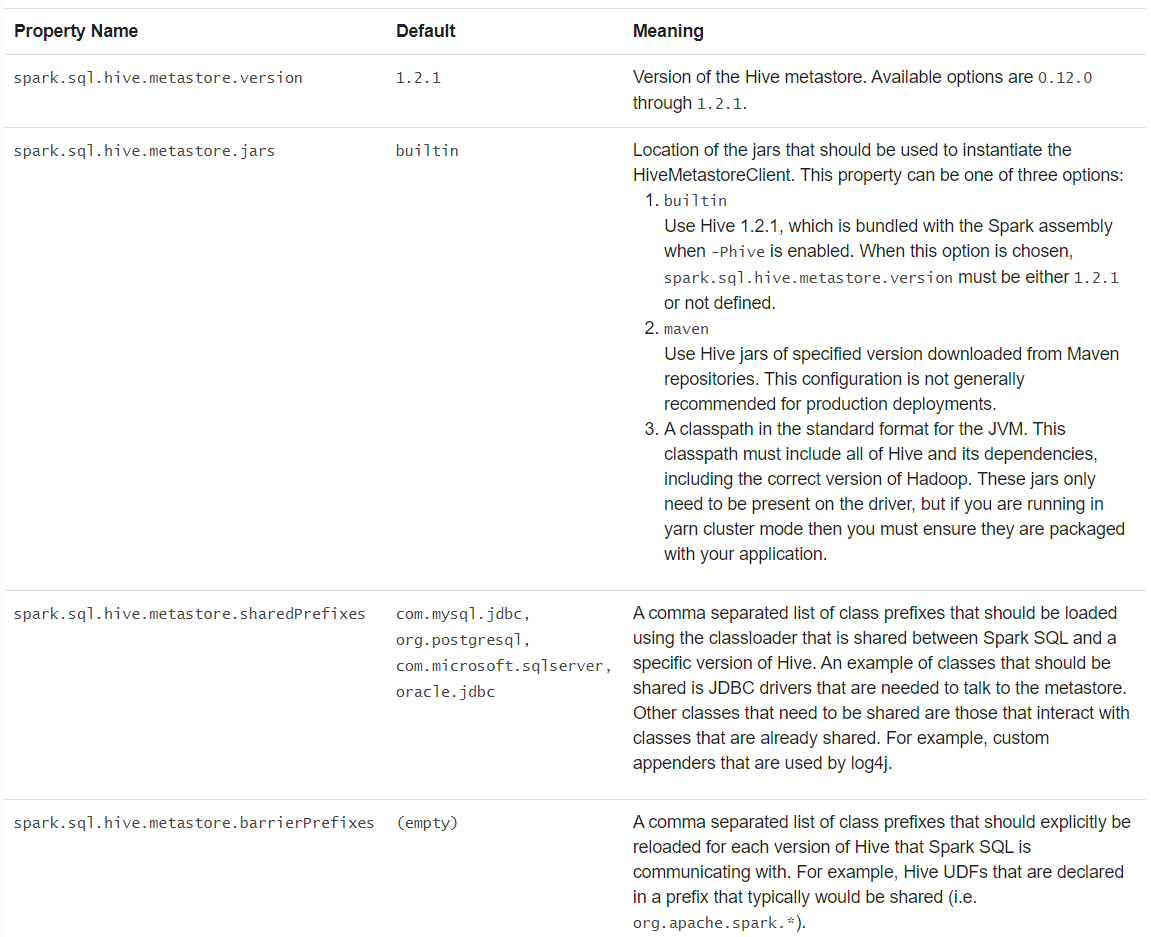
注意:Spark 3.0提供了对Hive3.0的支持。
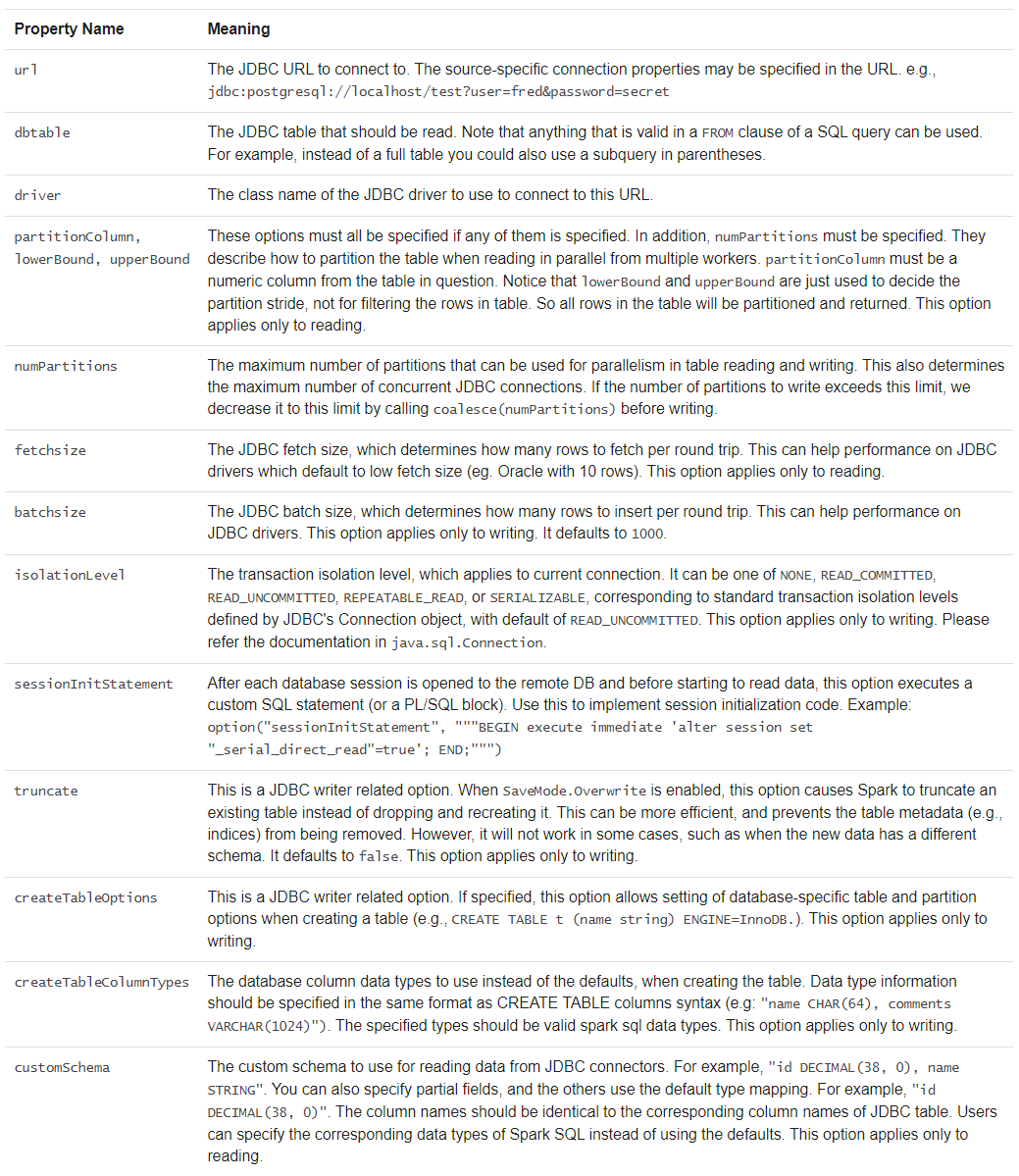
(6) JDBC连接其他数据库
Spark可以使用JDBC连接数据库。尤其是使用JdbcRDD时。
不同于Spark SQL JDBC Server(用于向外提供Spark SQL查询能力),不用提供ClassTag。
需要将相应的驱动放置在类路径下。
如:
1 | bin/spark-shell --driver-class-path postgresql-9.4.1207.jar --jars postgresql-9.4.1207.jar |
连接时,需要提供用户名和密码。
根据需要进行以下配置: 大小写敏感
1 | // Note: JDBC loading and saving can be achieved via either the load/save or jdbc methods |
(7) 故障排除
在所有节点的compute_classpath.sh包含驱动程序
因为Java的DriveManager在安全检查时会忽略对原始类加载器不可见的驱动。
一些数据库将所有名称转换为大写,Spark SQL需要使用大写名称引用。
4 性能优化
(1) 内存缓存
使用spark.catalog.cacheTable(“tableName”)或dataFrame.cache()缓存表。
spark.catalog.uncacheTable(“tableName”)释放缓存。
Spark只扫描需要的列并自动压缩,以减少内存占用和GC压力。
可以使用setConf或SQL的SET key=value配置。

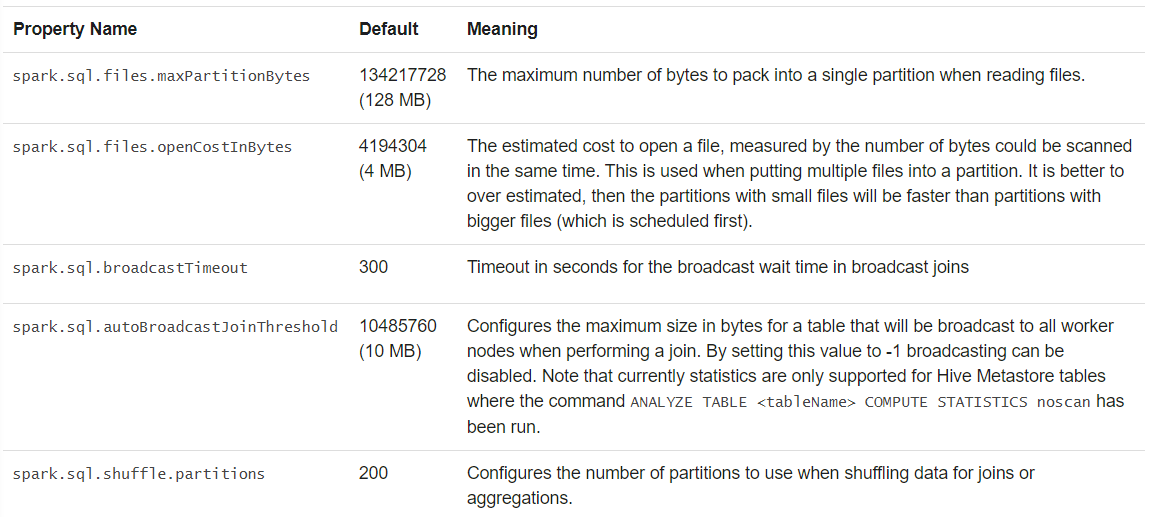
(2) 其他配置选项
以下优化选项可能在后续版本中移除:
(3) SQL查询的广播提示
Spark广播可用于表或视图间的join操作。
即使广播数据量超过spark.sql.autoBroadcastJoinThreshold配置,Spark还是会使用broadcast hash join(BHJ)。
当两张表都广播时,Spark会广播统计只较小的一个。
对于不支持BHJ的情形(如full outer join),不保证使用BHJ。
嵌套循环的广播依然遵守该规则。
1 | import org.apache.spark.sql.functions.broadcast |
5 分布式SQL引擎
可以通过JDBC、ODBC或命令行,使用Spark SQL作为分布式执行引擎,无需编写其他代码。
(1) 运行Thrift JDBC/ODBC服务器
Thrift JDBC/ODBC对应于Hive 1.2.1中的HiveServer2。可以使用Spark或Hive中的beeline脚本测试。
在Spark目录中启动服务器,接收所有bin/spark-submit的参数和配置Hive的–hiveconf
1 | ./sbin/start-thriftserver.sh |
默认监听localhost:10000,可通过以下方式修改:
1 | // 方法一:环境变量 |
使用beeline测试:
1 | // 启用beeline |
需要输入用户名和密码:
非安全模式
输入用户名和空白密码
安全模式
服务器支持使用HTTP发送thrift RPC 消息,可通过系统属性或hive-site.xml配置。
1 | hive.server2.transport.mode - Set this to value: http |
(2) 运行Spark SQL CLI
用于在本地模式运行Hive Metastore服务。
不能与Thrift JDBC 服务器交互。
1 | // 启用CLI |
6 使用Apache Arrow、用于Pandas的PySpark指南
略
7 迁移指南
(1) 版本迁移
略
(2) Apache Hive兼容性
版本2.3.0基于Hive 1.2.1支持。
可以通过配置,支持版本0.12.0-2.1.1
1) 在已有Hive仓库中部署
不用更改Hive配置
2) 支持的Hive特性

3) 不支持的Hive特性

8 参考
(1) 数据类型

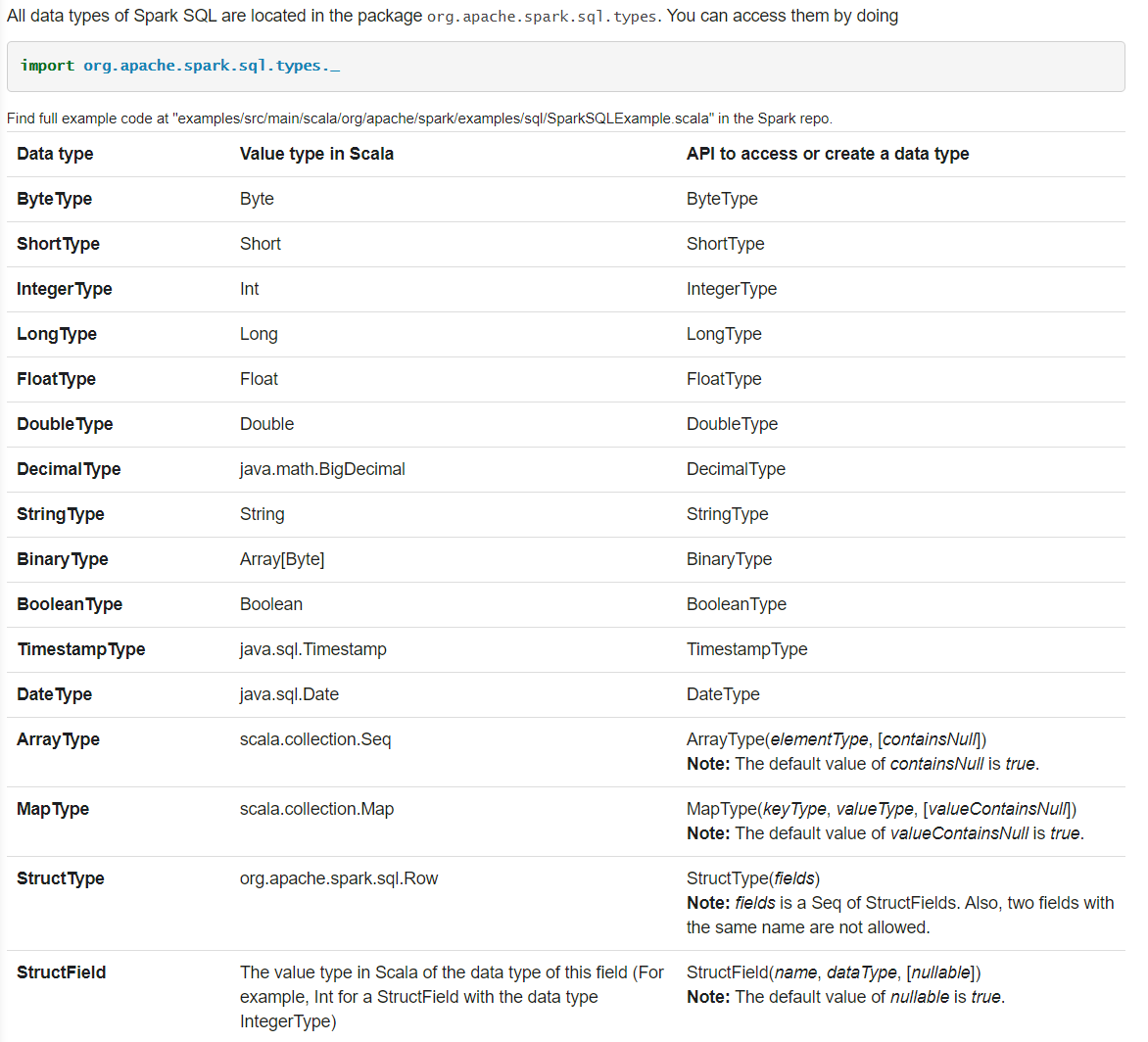
(2) NaN语义
表示not a number,用于浮点型或双精度类型。
- NaN = NaN,结果为true
- 聚合时,所有NaN分为一组
- 连接时,被当做普通值处理
- 升序排列时,排在所有数值之后。
参考资料
高基数:集合的基数,是其元素个数概念的推广。
Spark SQL, DataFrames and Datasets Guide